
Authoring agentic applications: to code or to prompt?

In a prior blog post, I talked about two scenarios where my exercise analysis application interacted with an LLM. In this blog post, I want to explore situations where, with the current state of the art, it makes sense to offload application logic to an LLM, and where perhaps it does not make sense to do so.
In other words, as a developer, when should I write code and when should I offload logic and integration to an LLM?
Note: I use LLM and model inter-changeably, mostly using models going forward for the rest of this post.
When offloading might make sense
In one scenario, I refactored my code where I offloaded pagination logic to the model, as I made a simple API interface and provided instructions to the tool on how to take advantage of that interface. This scenario makes sense because the pagination logic exposes how to retrieve incremental amounts of data to the model. The model can then make a determination of how much information is needed for the particular request.
For example, I’ve been working through adjusting my heart rate zones based on lactate threshold. While there are methods of calculating the lactate threshold heart rate (LTHR) value, I figured I could do that with my Strava MCP server setup.
I’m interested in calculating my LTHR. I have Strava data that you can use to help in calculating it. What is my LTHR based on my recent running history?
When entering that prompt, I got the following in Claude Desktop.
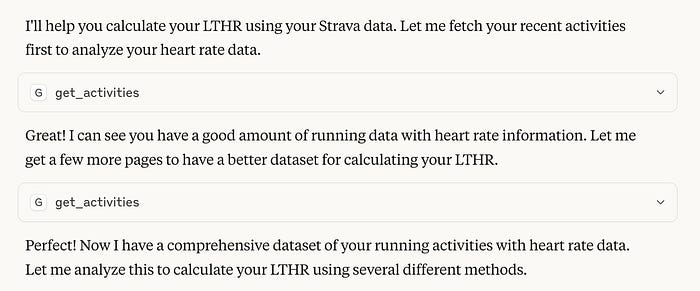
The application recognized the need for more data than what was retrieved in a single call and made a second request for additional data. After determining that it had sufficient data, it then proceeded to perform the analysis to produce not just the LTHR value but also recommended heart rate zones based on the computed value.
So it made sense to provide a clean interface to the model with instructions on how to leverage that interface, e.g. page number, items per page. More generally, it could make sense to rely on a model when:
dynamically configuring parameters for functions, like with paginated API requests
performing dynamic workflow orchestration, e.g. cases where it would be hard to define the workflow as a state machine
executing tasks that require some amount of contextual judgment or interpretation, such that a simple switch/case would be insufficient
This list is by no means exhaustive, and I’m sure there are plenty of situations where it depends, but it’s a starting point.
When writing code might make more sense
In another scenario, I talked about this “aha” moment when I leveraged two different MCP servers — one for Strava, one for weather data — and was able to conduct analysis, integrating the two data sources, without writing a single line of integration code.
I shared a screenshot of the analysis I did in Claude Desktop without much inspection of the report itself. After publishing that blog post, a number of colleagues reached out, not to talk about the post itself, but to remark that “wow, you run a lot”. At first, I thought, “yes, I do”, but with more than one person making that comment, I got uncomfortable. Then on looking at the data a little more closer, I noticed perhaps what others were seeing.
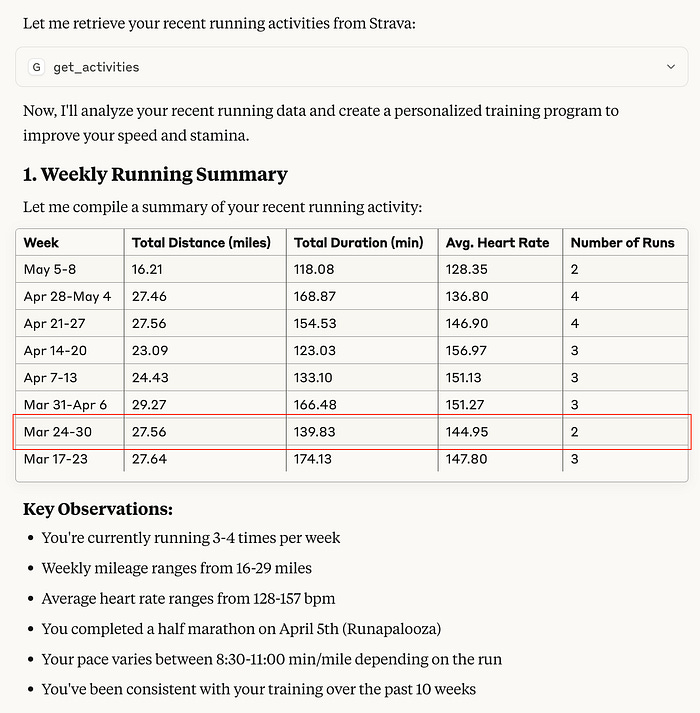
Looking at March 24–30 … no, I did not run two half marathons that week, averaging 1 hour and 10 minutes for each half marathon. With those runs, I would be 13-14 minutes from world record pace! I overlooked what has been obvious to the generative AI community since the beginning: LLMs are terrible at math.
So in this scenario, it made sense to go and write some code to perform that discrete analysis, rather than wrestling to prompt engineer the model, beseeching it with prompt tags like:
[IMPORTANT] Ensure the calculations are accurate; data cannot be misreported.
Furthermore, with the aid of an AI coding assistant, I was able to quickly update my Strava analysis class to analyze the running data on a weekly basis and add that function as a tool to my MCP server.
After deploying that tool to my MCP server on Lambda, I restarted my Claude Desktop to detect the new tool. I then simplified my prompt and got the following:
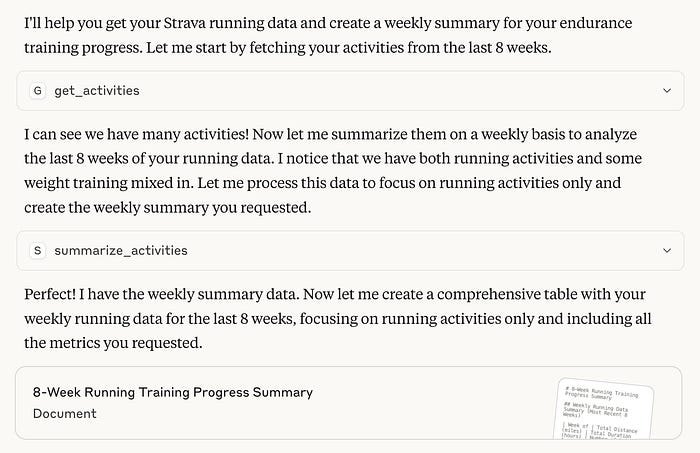
After it got the activities, it then used the new tool to perform analysis on the retrieved activities. And looking into the summary document, I got a table that contained accurate data (distance and run count verified) with insights based on proper data.
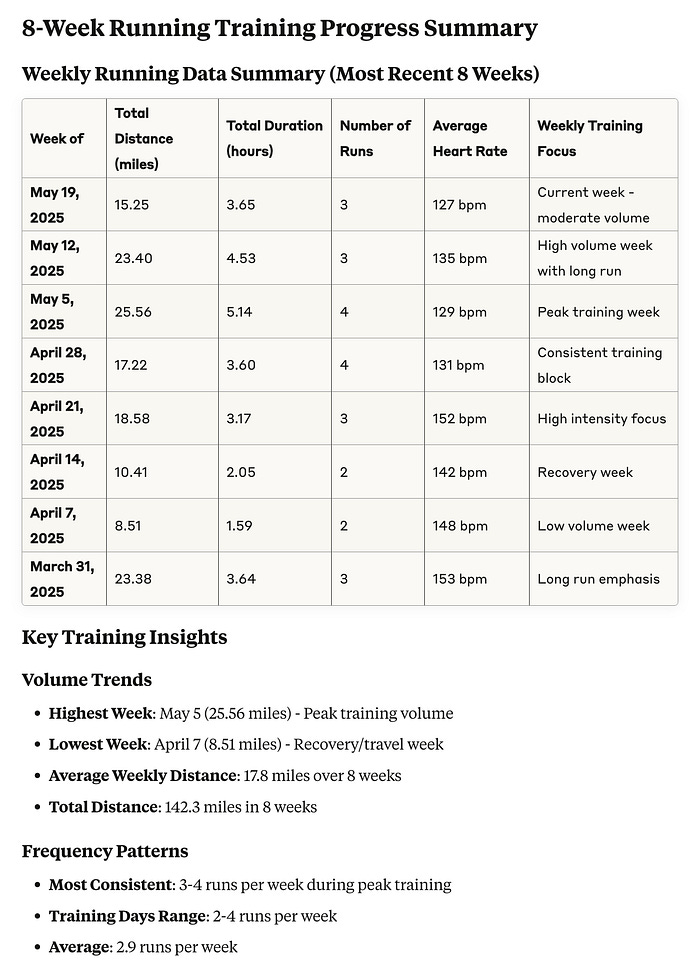
And a pretty nice summary with key highlights and patterns.

So back to the point at hand, LLMs are good are generating understanding and insights from calculated data, but they are not good at the math itself. Yes, they can generate code to do that math, but I’ve found even that to be problematic, especially with context window limitations. So perhaps it makes sense to write code when:
performing analysis where accuracy is critical, e.g. mathematical calculations, statistical analysis, data transformations
executing tasks that require precise and repeatable outputs
applying algorithms where correctness is paramount
Again, not exhaustive, and may change in the future, but a starting point, for now.
The pendulum swings
So I talked through scenarios where it might make sense to lean on the model to generate insights and other scenarios where it might make sense to write code to generate accurate and repeatable outputs.
I gave a talk earlier this week where I talked about the rapid pace of innovation in this space. I mention this because it’s possible that these models dramatically improve tomorrow and shift the pendulum in favor of moving more of that logic into the model (production considerations like performance, testing, deployment, and cost aside).
For example, Anthropic just announced Claude 4 today, and who knows if that model has improved such that what I write here is no longer valid.
For now at least, I think there is going to be this pendulum swing between the need for deterministic and accurate outputs via code and the desire for adaptive reasoning via models. Perhaps someday these models will get so good that they do both the math and the adaptive reasoning well. Perhaps that’s when the race for AGI will have been achieved.
Finding our place as architects and developers
A quick aside before I wrap up. At the event I mentioned above, I spoke broadly about generative AI architecture patterns, agentic AI, and the rapid evolution of MCP in this space. A colleague and I then talked to one particular attendee, a backend developer, who was still confused about how a developer navigates this emergent space.
I started by saying that this is simply about inputs and outputs, and that this attendee already knew these patterns. Models take a prompt (input) and produce completions (output). It’s the same as API endpoints that take a request (input) and produce a response (output).
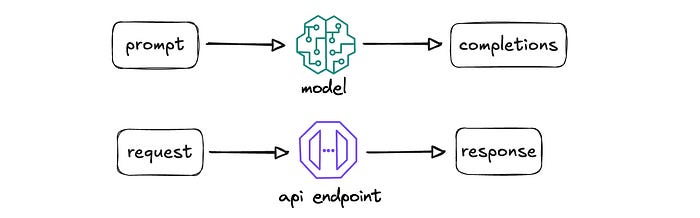
While researching a bunch of agentic frameworks, like LangGraph and Strands Agents, I realized it came down to one simple idea. The frameworks are simply constructing a prompt with sufficient context to get a good response from the model. In other words, they’re constructing a request body to be submitted to an API endpoint that then returns a response body, hopefully a useful one.

I also re-iterated that many of the concepts that are popping up with agentic AI are not necessarily new but are perhaps reskins to prior art with microservices (and prior to that, service-oriented architecture), event-driven architecture (and enterprise service buses, message-oriented middleware), etc.
Furthermore, as we look at agents and agent networks, I suspect we’ll have similar needs of using the strangler pattern to break down “agent monoliths” with too many tools and resources into “agent microservices” and will need service discovery mechanisms in these broader agent networks. MCP is currently discussing this (1, 2), A2A has this built-in, and AWS just blogged about open protocols for agent interoperability.
I mentioned to this attendee that I am by no means a machine learning engineer nor a data scientist. I know enough to be dangerous but definitely don’t know enough to go and train or fine tune my own models for production usage.
However, I do think I am a decent application architect and developer. And with those skills, I think about where I’m best suited to add value in this space. To that end, I adapted the “generative AI value chain” from this blog post on LLMOps to speak to where certain personas might play. In my view, application architects and developers play solidly on the right with agents and agent networks. Why? We’ve got prior skill in building microservices and figuring out how those services inter-operate, with security, reliability, and scalability in mind.
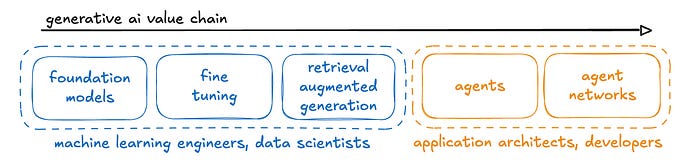
I think the right side of this value chain is ripe for innovation and thought leadership. So all the application architects and developers should be excited because it’s our turn to play a big role in the next wave of innovation for agentic applications!
Conclusion
To code or to prompt. I covered some considerations that architects and developers need to keep in mind when building agentic applications. If you need repeatable, accurate, deterministic execution, then write code. If you need to apply some amount of dynamism or reasoning into your workflow, then consider (and test) the use of a model.
But the pace of innovation in this space is astounding. The current state of the art changes every few months with new model releases and could alter the assumptions about what should be written as code or submitted as a prompt to a model. The pendulum may very well swing back and forth as developers author their applications to meet the requirements of the business and adapt to using the latest model releases.
Architects and developers can get frazzled in this evolving landscape, but recognize the underlying patterns — patterns we already know. This is an exciting opportunity for architects and developers to innovate and lead the charge!
Resources
Note
This article was originally published on Medium.